ICRT
In-Context Imitation Learning via Next-Token Prediction
TL;DR: Casting in context imitation learning as a next token prediction problem.
Overview
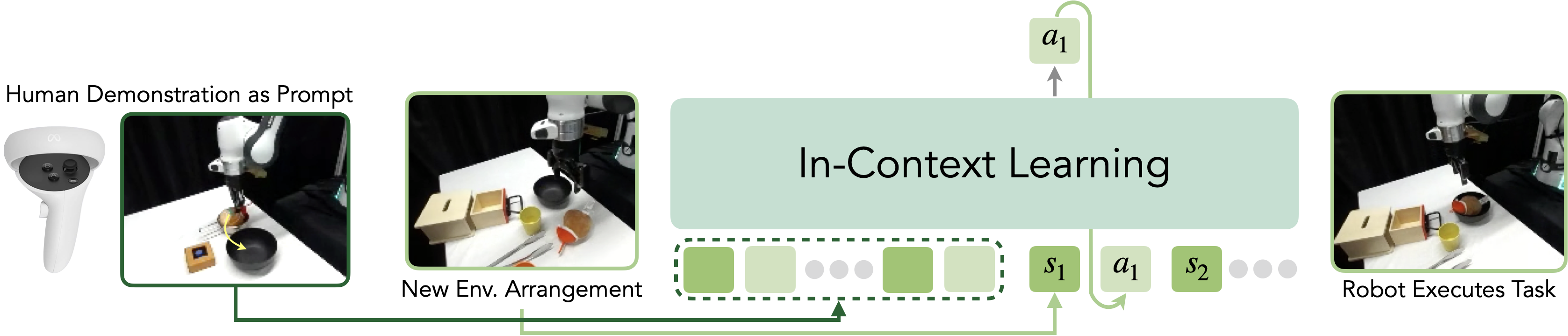
In-Context Robot Transformer (ICRT): A robot foundation model with in-context imitation learning capabilities. ICRT performs next-token prediction on large-scale sensorimotor trajectories. At inference time, it takes raw sensorimotor trajectories of human teleoperation demonstrations as prompts, enabling the model to execute new tasks with real-time continuous control, without requiring fine-tuning.
Methodology

We encode the robot observations (left and wrist camera observation) with a pre-trained vision transformer. Additionally, we encode proprioception with a multilayer perceptron (MLP). We concatenate the visual latent and the proprioception’s latent and use attention pooling to extract a feature to represent the current state. We use another MLP to encode the action taken at the current step as the action feature. We concatenate multiple trajectories of the same task and randomly sample the first k trajectories as the prompt. We encode the trajectories via a causal transformer, and the model decodes a series of tokens. We decode the tokens that are at the position of the state features to generate the next h = 16 action via a MLP.
Model Architecture and Training
Transformer Model We consider a randomly initialized Llama2 model of 12 layers with a latent dimension of 768, which takes as input the sequence of state and action features that are produced by the modality-specific projectors. We add MLP decoders to produce state and action outputs from the last layer of the transformer at the appropriate positions.

Multi-Task Dataset We utilize the existing large robotic dataset DROID and a multi-task dataset manually collected in our robot setup, which we name ICRT-Multi-Task (ICRT-MT). Many trajectories in the DROID dataset are collected in a single-task setup, where only one task can be completed in the given environment. We find that multi-task data is crucial for the model to learn from the prompt. Therefore, we manually collected a multi-task dataset ICRT-Multi-Task (ICRT-MT) using the DROID setup. This dataset has 1098 trajectories in total, and contains 26 tasks with 6 primitives. Objects used in the data collection and examples of the primitives are shown in the Figure above. In ICRT-MT, each environment is set so that there exist more than 2 possible tasks for the current observation. ICRT is pre-trained on the DROID dataset and fine-tuned on ICRT-MT.
Loss Function During the training, we sample n trajectories for a total sequence length L as the input. We randomly select the first k trajectories and label them as the prompt within the sequence. At least one complete trajectory is included in the prompt. We only compute action prediction with L1-loss for the actions after the prompt trajectories.
Experiments
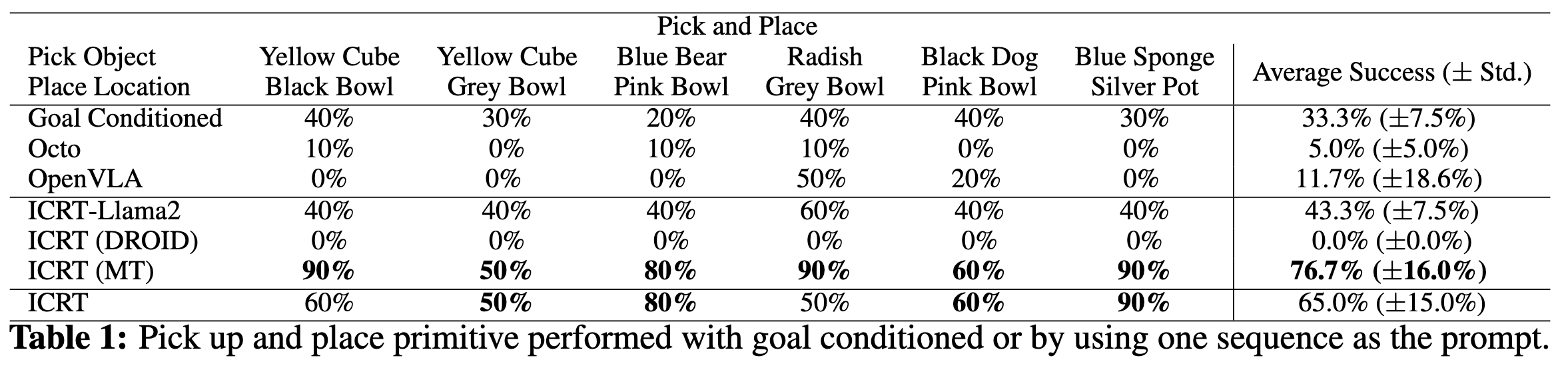
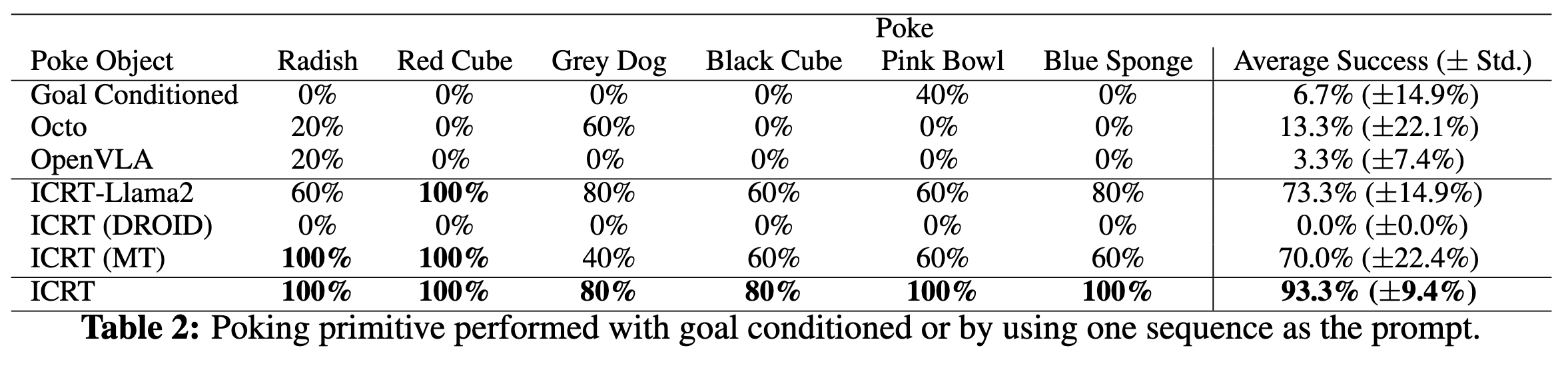
We consider two action primitives: a pick-and-place primitive and a poking primitive. For each action primitive, we design six unseen tasks, with three tasks evaluating in-domain object generalization and three evaluating on objects unseen during training. We compare the performance of ICRT with three variants of ICRT and three baselines listed below.
ICRT Variants
- ICRT-Llama2, a pre-trained Llama2-7B language model fine-tuned on ICRT-MT with LoRA;
- ICRT (DROID), a randomly initialized Llama2-Base model trained only on the DROID dataset;
- ICRT (MT),a randomly initialized Llama2-Base model trained only on the ICRT-MT dataset.
Baselines
- Goal-conditioned, a policy trained with the dataset where each sample contains only one trajectory and the goal observation and state pair are always prepended to the sequence;
- Octo, the state-of-the-art goal-image observation and language conditioned policy fine-tuned on ICRT-MT;
- OpenVLA, the state-of-the-art language conditioned multi-task imitation learning algorithm fine-tuned on ICRT-MT;
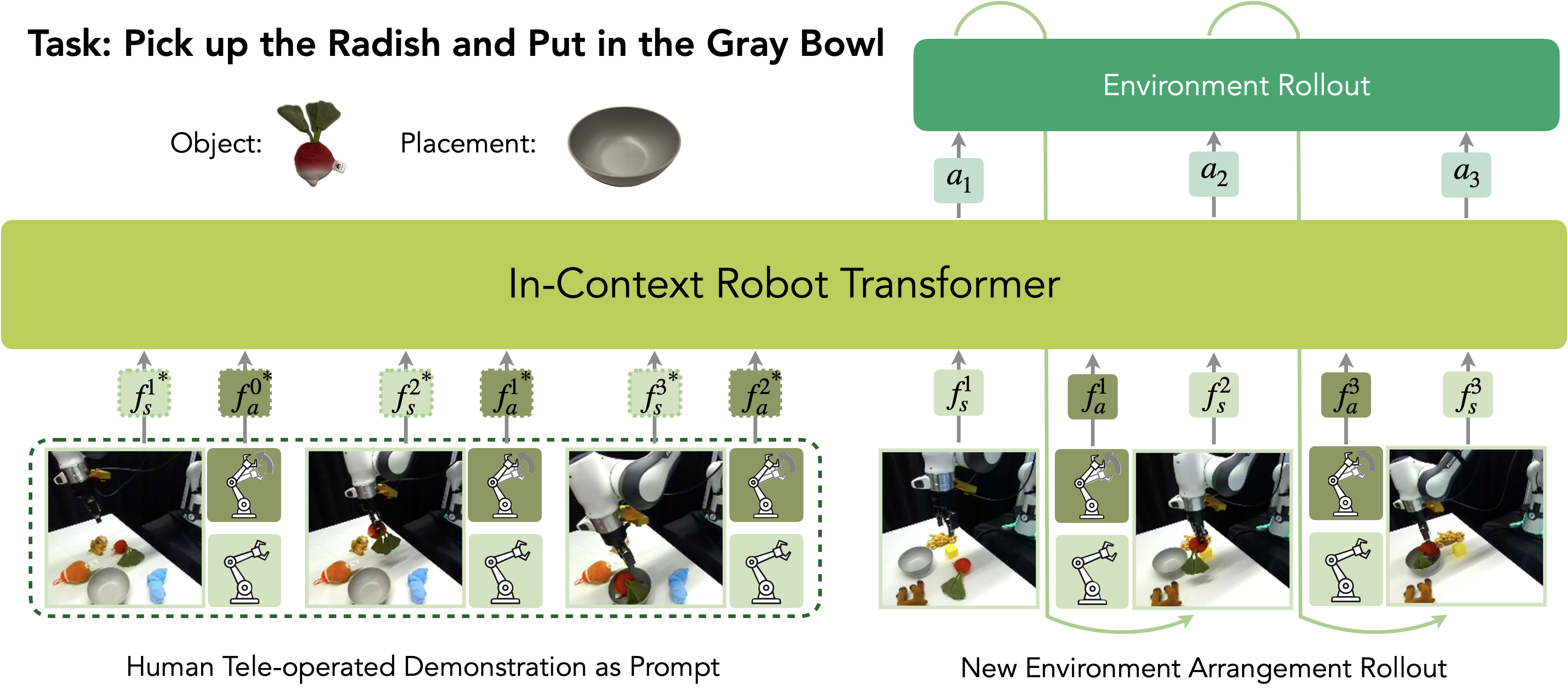
Inference For each task, we collect human-teleoperated robot demonstrations in a different environment as the prompt for running the experiment. We provide one or more human-teleoperated demonstration in the form of robot sensorimotor trajectories (formatted identically to the training data), along with the current image observations and the robot’s proprioceptive state as inputs. The model then predicts the next action, which is executed by the robot. After each action, the policy receives updated image observations and proprioceptive state, allowing it to iteratively predict and execute subsequent actions.
Results We present the results in Table 1 and Table 2. The results suggest that ICRT outperforms the other variants and baselines. ICRT is able to generalize to unseen tasks and objects, even in environments that differ from the prompt.
Example Videos of Tasks
Citation
If you use this work or find it helpful, please consider citing our work.
@article{fu2024icrt,
title={In-Context Imitation Learning via Next-Token Prediction},
author={Letian Fu and Huang Huang and Gaurav Datta and Lawrence Yunliang Chen and William Chung-Ho Panitch and Fangchen Liu and Hui Li and Ken Goldberg},
journal={arXiv preprint arXiv:2408.15980},
year={2024}
}